
Quiz portions: Up until Lecture 8.
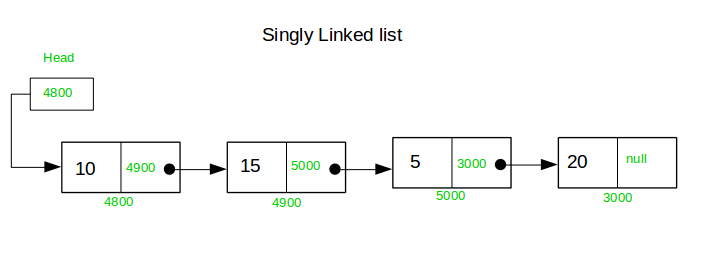
We had seen a pictorial representation like the one here.
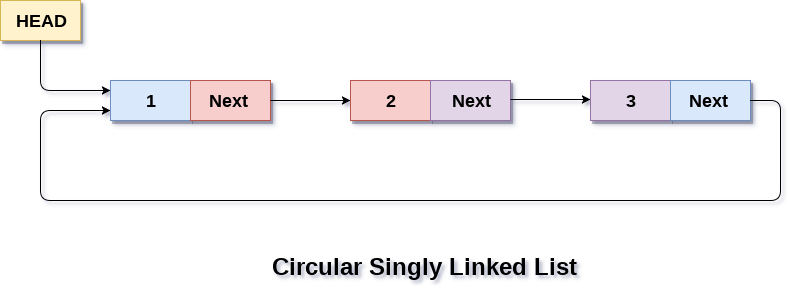
We also have the concept of something known like a circular linked list.
That looks something like this.
Q. How will the header look?
Let’s go step by step.
How should an circular list look?
clist = null to begin with.
For a single one, we have an empty guy pointing to one cell. That cell will point to itself.
In general, we don’t have a “start” or “end”. The “header” in this case can point to anything.
Note that in terms of structure, neither list has an advantage over the other. So, why do we care?
We will use this quite often.
What’s the difference between singly and doubly? Each cell has a data and two addresses. More tightly linked to its neighbours. In singly linked list, we could only go forward. Here, we can go in both directions. (Pic)
Furthermore, this can also be made into a circular (doubly) linked list, if needed.
→ Array, dense representation, keeps only coefficients, not the exponents. (Recall Lecture 3)
→ Or - we can use a sparse representation. Zero coefficients not stored. Now, we store exponents as well as coefficients.
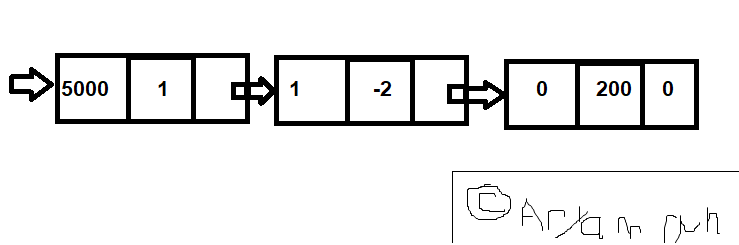
Example, \(p(x) = x^{5000} - 2x + 200\).
(Pic)
Should we use singly linked or doubly? Why?
Doubly uses more memory as it keeps one more address. If we use doubly, there should be some good redeeming factor.
Moreover, the representation shouldn’t change, id est, it should remain sparse. For example, if I add \(q(x) = 2x^{5000} + 2x + 100\) to \(p(x)\), I don’t want a \(0\) coefficient to appear in the sum.
Now, let us go to another example.
Matrices: sparse matrices
Let us assume \(n \times n\) matrix for now.
When can we call a matrix sparse?
We need a definition. We want “very few” nonzero elements. In many applications, we do get sparse matrices. For example, a network of people in the world who are friends. There will be many \(0\)s as many people don’t know each other. <insert self deprecating joke here>
For example, take the following matrix
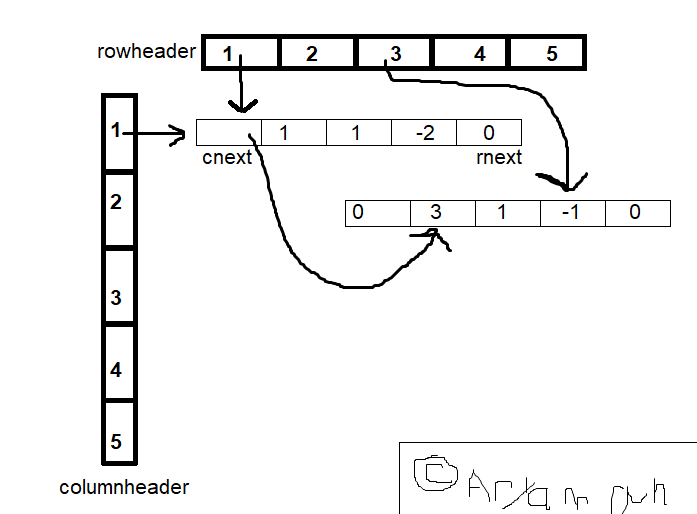
\[A = \begin{bmatrix} 2 & 0 & 0 & 0 & 0\\ 0 & 1 & 2 & 0 & 0\\ -1 & 0 & 0 & 0 & 0\\ 0 & 0 & 0 & 5 & 0\\ 0 & 1 & 2 & 0 & 0\\ \end{bmatrix}.\]We can completely describe the above using triples, the coordinates and the values. (r, c, v) where r is the row number, c the column number and v the value.
2D array is not a good choice for this. We assume that the sparsity is random and using a 2D array would take up too much space as we have no idea about the location of the values, a priori.
We can represent this using a singly linked list structure like before. Just that now we’ll keep three data, instead of two.
What are the operations can we do?
In the case of dense representation, 1. can be done in \(O(1)\) time. Here, we don’t know. We’ll have to check throughout the list and possibly go till the end, in the worst case scenario. If not there, then we tell that it’s a \(0\). Thus, this is \(O(r)\) → \(r\) is the number of nonzero elements.
Similarly, even for 3., we get \(O(r)\).
This doesn’t look very good. We’re still getting \(O(r)\), not better than the array case. Clearly, singly linked lists aren’t very nice after all.
We want to be able to extract elements, rows and columns quickly. Assuming that most operations on matrices will use this, this should be good.
See the pic here for an incomplete representation of the matrix above and try to understand.
If there’s some empty column/row, its column/rowheader will have null.
This increases speed of traversing. However, we do use more memory, making those headers.
Now, we could also add more locations, cprev and rprev which refers to the previous location of a filled column (row) entry. However, now we use even more memory. Thus, if we’re doing this, the expectation is that we should get even greater speeds.
Professor shows the slide containing different linked structures and the time complexities of different operations.
To delete an element, keep a track of p and prevp. (p is the pointer of the value you want to delete and prevp is the one before.)
To delete p, we just change the next of prevp to the next of p.
If we didn’t keep track of this prevp, we’d have to make two trips.
Traversing backwards is \(O(n^2)\). (List with pointer to head.) Why?
First, take \(n\) steps and get till the end. Take its address.
Then, go till the cell whose next gives this address. This’ll take \(n-1\) steps.
Now, then we go to the \((n-2)^{\text{th}}\) guy using \(n-2\) steps and so on.
This takes \(1 + 2 + \cdots + n = \frac{1}{2}n(n+1) = O(n^2)\) time.
(Instead of the address thing, we could’ve also used a counter. Same effort.)
Q. Can we make this better? Constraints: can’t use any other data structure or tamper the list in any way.
Look at the table and tell professor in the next class whether you agree with all the complexities for the operations or whether you have anything better.
isParse() which gives yes/no. That is, come up with a definition to classify polynomials as sparse or not. \(\sim O(\sqrt{n}).\) (Not saying that the time complexity of isParse() is \((O(\sqrt{n}))\). The number of nonzero coefficients should be around \(\sqrt{n}\).)display() → ascending/descendingDon’t write code. Better questions → can my data type do these things? If not, change data type.
Answer the same stuff for matrices with their basic operations. Things like trace, positive definite, et cetera.
Another question with sparsity → how much does the sparsity change after doing some operation? Does it still remain sparse?
Thanks to Andrews Varghese for pointing out a sentence that was originally phrased ambiguously.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}