
Today’s content → stack.
x + y * y % 9 <= y && y <= 5 || x == 10Q. Why do we care how it’s evaluated?
If an expression written is ambiguous, it’s of no good.
→ Prof shows a table: “The operators in C++ with their attributes are given in the following table.”
There’s only one ternary operator. (Trivia fact.)
How do we interpret:
x + y * z % 9 <= y && y <= 5 || x == 10
We put the number of the operators from the table and evaluate from left to right. If the one of the right is greater, then we do the right operator first.
Pic
Suppose y = 9, z = 3, x = 6.
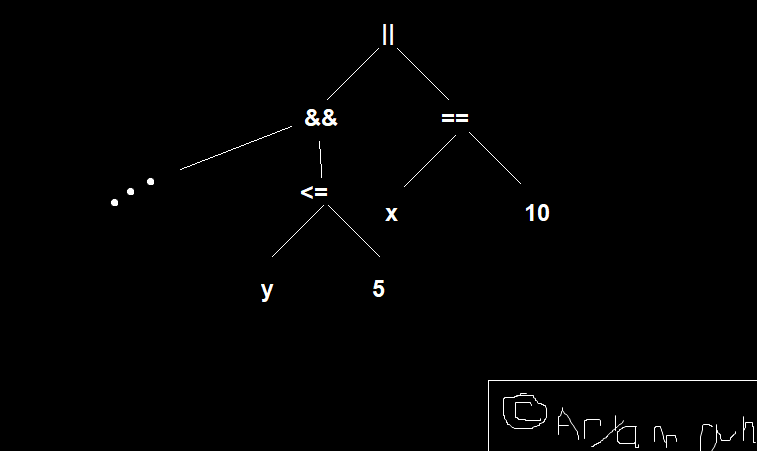
Refer to the picture and see that this will be evaluated as follows:
6 + 9 * 3 % 9 <= 9 && 9 <= 5
6 + 27 % 9 <= 9 && 9 <= 5
6 + 0 <= 9 && 9 <= 5
6 <= 9 && 9 <= 5
true && 9 <= 5
true && 9 <= 5
true && false
false
(I skipped the last part || x == 10. Easy to do that as well.)
Note that if we had just put brackets, then we clearly could’ve done it. Point is how we interpret in the absence of brackets.
We can represent this using a tree.
Pic
Note that to compute any node, we must compute its children. This forces the expression to be evaluated in the way it should be, according to the table.
Different notations:
Consider: a + b * c - d → infix currently.
Make this postfix: abc*+d-
(Note that priority order was: * > + > -)
This makes it easy to evaluate. In the earlier, we had to go back and forth. We had to check whether anything on the right had a higher number.
In this case, we have a linear reading of how to evaluate.
Q. Given any infix expression, can we convert it to postfix?
Traditional steps:
Note, we might get an expression like a * b * c * d. How do we convert this? This depends on the associativity of the operator. Since * is left associative, it is computed as (((a * b) * c) * d).
This would be different if it were right associative.
Given an expression a + b * c - d.
We read the expression. If we see any operand, just start writing it in a line.
If you have any operator, start stacking it up.
If the newer operator being added is less (in precedence) in priority than the last operator sitting on top, eject the topmost operator and put it in the line. In fact, continue throwing out the operators on top until the operator left is smaller.
Once the expression is all done. Throw out the operations to the line.
This stack structure is called LIFO - last in first out.
isempty()push(elm)pop() → returns the last element after deleting (stack changes)peek() → returns the last element without deleting (no change)isfull() → checks whether there’s space in the structure. Normally, not used but should used in a case like static array.Let us now write a pseudo-code for this infix→postfix conversion.
incoming_op = 0;
while(string s){
if s is an operand: print s
if s is an operator:
incoming_op = s
while(precedence(incoming_op) <= precedence(top_of_stack_op)){
print(pop()) // removes the operator as well
}
push(incoming_op)
}
Thus, given any implementation of stack, we can print out postfix.
First question → given an expression, is it a valid postfix expression to begin with?
This is also done using stack.
As long as we’re reading operands, keep putting them in stack. If you reach an operator, pop the last two values of the stack and put operand-1 operator operator-2 instead. (Example, replace a and b with a+b in case you read a + and the last two elements of the stack were b and a.)
He’s gonna discuss the assignments and tell the common errors.
As soon as you get the list, just sort it. Don’t do it after queries.
Note that C++ has its own inbuilt sort. Don’t have to write your own. Can sort structures and all as well, just need to define <=.
So, one can make a student structure (storing marks and roll number) and define <= based on marks.
There were many if in code. Samad will share his wisdom on how to write clean code.
Suppose A is the sorted vector.
If we want the marks in [x, y], we should first find an index i such that A[i] >= x and A[i-1] < x.
To take care of end cases, put two dummy students → one with marks \(-\infty\) and one with \(\infty\). (Put integer_max or whatever.)
With these two dummy students, we don’t need any extra care for corner. You’ll always get the i you desired.
Make sure that your search index starts from 1 then.
He skips. No time. :(
brief thing for Q2:
Keep a track of min_so_far
Then something about max_selling but he rubbed the board too quickly.
Many did this correctly but code was inefficient.
Many have done the recursion thing. max_price(n) = max(max_price(n-i), max_price(i)) over all valid i or something.
However, implemented like this will be some exponential thing.
Instead of this, just keep storing the values from 1 to n as you go using an array.
What most people have done:
Suppose there are arrays \(A_1, A_2, \ldots, A_n\).
They have taken arrays \(A_1, A_2\) and merged them. Taken \(A_3, A_4\) and merged them. And so on. This gives \(2n\) sized arrays. Then merge them two at a time and so on.
This is the “correct” method.
Implementation normally was tough in a bottom-to-top method.
However top-down is far easier to implement. The same way we do it in merge sort. First, merge the first \(k/2\) arrays and then the last ones.
In fact, this is merge sort. It’s just the “fundamental unit” of merging is different. However, the difference is that when we merge two integers, is just \(O(1)\). (Just one comparison.)
On the other had, merging two arrays itself is \(O(n)\).
Thanks to Andrews Varghese and Rohan Gupta for pointing out errors that had originally crept in.
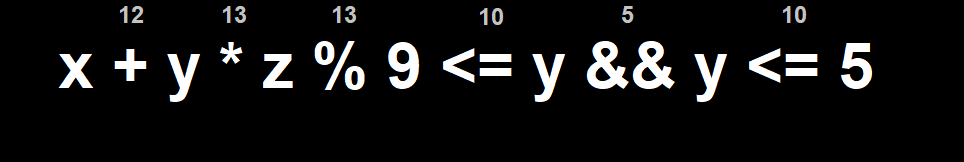{kind=link}
{kind=link}