
Next four lectures:
FIFO - first in first out. Recall that stack was LIFO.
Operations
create() → create an empty queueisEmpty() → booleanisFull() → if the storage is “very finite”, then we might keep this as wellinsert()delete()Specific way to implement the last two operations. The difference here in queue lies in the way of implementation.
Queue has two ends -> front and rear.
Also join at the rear of the queue and get service from the front.
If we had the input: “cs-101”, “cs-213”, “ma-214”, we get the queue:
|cs-101|cs-213|ma-214|
If we delete, we get:
|cs-213|ma-214|
So far was an abstract definition.
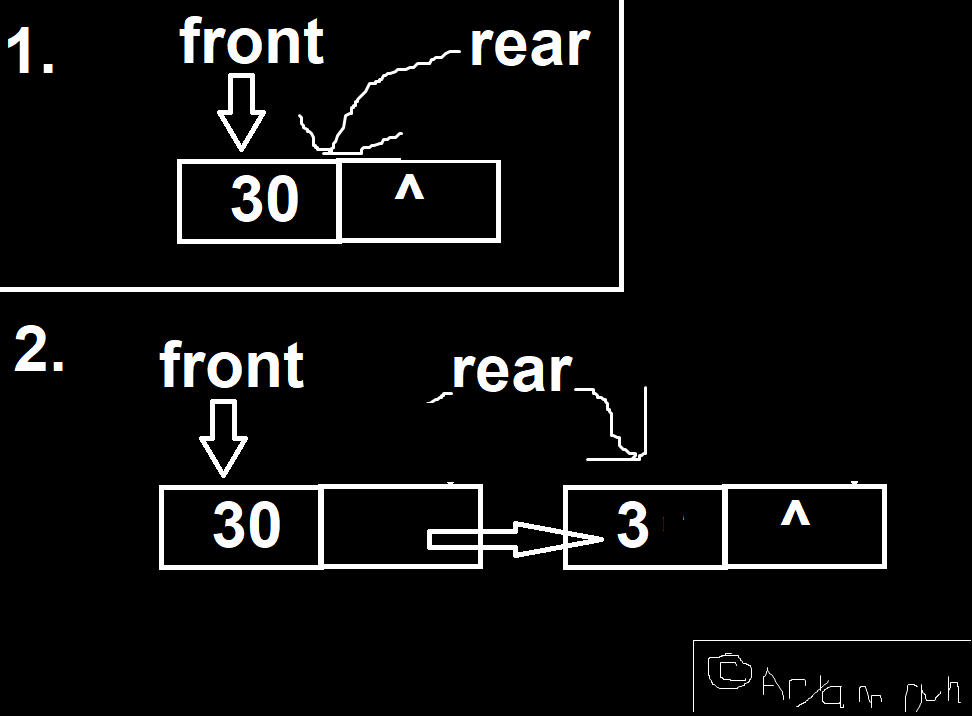
So, we have an array Q and two variables front and rear.
How do we implement an empty queue? Compiler will not keep an array empty.
Should somehow ensure that front and rear make it so that we can’t access the array.
front = -1 and rear = -1 works. (Note that front = 0 is not good because 0 is a valid entry.)
Our invariant that we want to maintain: elements are in \(Q[\text{front}], ..., Q[\text{rear}]\).
However, now we get that if front = rear and > 0, we’ll get that it has a singe element. However, we started with front = rear = -1 to mean empty.
There’s one more problem with a linear array representation → if we do a lot of inserts and deletes, we may end up having the first \(N - 1\) entries “empty” and having only one more place left after which it gives an error that it’s full even though, it really is not. (\(N\) = size of array.)
Better to have a circular array representation. Use modular arithmetic to loop back. Better space utilisation.
However, most implementation will be forced for this: even if there are \(N-1\) elements, we say that the queue is full.
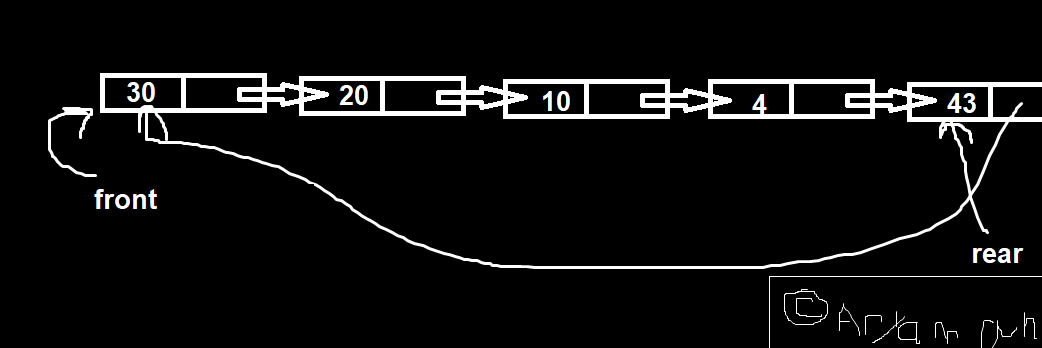
Single linked list.
Check this.
Circular linked list
Check this.
Note that rear->next is always front. So, we don’t need to keep both pointers. We ditch front.
Thus, if we want to delete: rear->next is to be deleted and rear updated accordingly.
Even insertion is done via some few pointer operations.
Example: graph where vertices are courses and directed edges tell you which course is a prereq for what. (Can’t have loop in this example.)
How do we traverse the graph?
Traverse: List every vertex exactly once.
We use a queue.
First, we put the root in the queue. Then we run a loop as follows:
insert(root);
while(!Q.isEmpty()){
x <- delete();
print x;
insert(all successors of x);
}
However, in the above, we might repeat stuff.
Thus, we also keep a visited boolean array.
This is called “breadth first traversal”.
Good for generating bit strings of length \(\le r\).
Note that the two bit strings of length 2 are: 10 and 11
The four of length three are: 100, 101, 110, 111
These are obtained by adding a ‘0’ or ‘1’ at the end of the original 2 bit strings.
Using this relationship, easy to generate a queue.
delete & print front
insert(Q[F] + "0")
insert(Q[F] + "1")
Data structure for efficient searching.
Optimum BST (Knuth vol. 1)
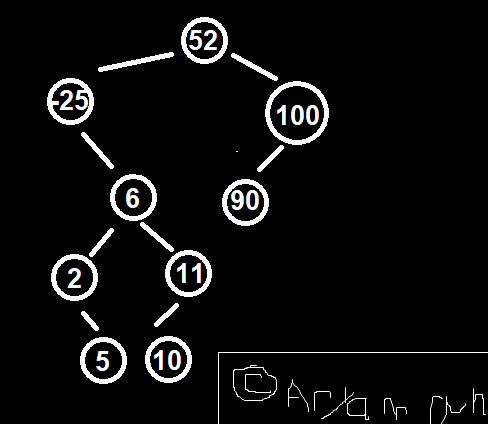
Suppose we have some array: {52, -25, 6, 100, 90, 11, 2, 10, 5}
root: special node of a tree: parent is itself
Everything else has a parent. Root is not the child of anything.
We start with 52 as a root. Then, -25 is smaller. -25 will be the left child of 50.
Then, 6 is the right child of -25. 100 is right child of 52. 90 is left child of 100. 6 is right child of -25. 11 is right child of 6. 2 left of 6. 5 right of 2. 10 left of 11. Pic
In our implementations, we won’t keep same elements. BST has the following properties:
Queries:
find(key)min()max()successor(x) \(x \in T = \text{Tree}\)predecessor(x) \(x \in T\)root(T)height(T)
\(\text{height}(T) = \displaystyle\max_{x \in T}(\text{path from root to }x)\).TO find min: keep going left from the root. Similar for max.
Complexity in both is \(O(\text{height})\).
How to find the successor? (That is the value that would occur after \(x\) if in ascending order. Successor of 6 in the above example is 10.)
Again \(O(h)\).
Question: Can we pick a root nice enough such that \(h \sim \log_2n\).
There are some trees that do allow this.
Suppose that we are given some fixed set. For example, the reserved keywords of C++. Lexicographic order is the way to order.
Can we make a BST whose \(h = \log_2n\)?
What word should we take?
If \(n = 50\), then we want \(h \sim 6\).
Idea: To keep the tree always balanced.
{kind=link}
{kind=link}
{kind=link}